
Lies diesen Artikel und viele weitere mit einem kostenlosen, einwöchigen Testzugang.
Für die Suche nach Duplikaten bietet Access einen speziellen Abfrageassistenten. Dieser liefert nach einigen Schritten eine Abfrage, mit der Sie die Duplikate untersuchen können. Wer etwas flexibler sein möchte und nach der Auswahl der betroffenen Tabelle und der zu untersuchenden Felder gleich ein Ergebnis erhalten will, wird in diesem Beitrag fündig. Und das Beste: Sie können die passenden Duplikate nicht nur gleich beim Anlegen der Parameter betrachten, sondern auch noch die Weiterverarbeitung in die Wege leiten.
Die Suche nach Duplikaten und das Entfernen der jeweils überflüssigen Exemplare ist gerade beim Zusammenführen von Daten aus verschiedenen Adressbeständen eine wichtige Aufgabe. Dies gilt umso mehr, wenn Sie die Adressen verwenden, um Kunden anzuschreiben – sei es per Briefpost oder per E-Mail. Wenn ein Kunde ein Anschreiben gleich doppelt erhält, wirft dies ein schlechtes Licht auf den Absender.
Und bei Anschreiben per Briefpost gibt man im schlimmsten Fall unnötig Geld aus, weil man den Kunden entweder bereits per E-Mail kontaktiert hat oder verschiedene Adressen des gleichen Kunden verwendet, von denen eine oder mehrere veraltet sind.
Die Suche nach Duplikaten im Adressbeständen sollte daher so flexibel wie möglich sein und ein schnelles Abgleichen von Adressen nach verschiedenen Feldern erlauben. Wenn Sie beispielsweise im ersten Ansatz Adressen von Kunden ermitteln, deren Name mehr als einmal auftritt, und dabei auf einen vierfachen Klaus Müller treffen, sollte es schnell möglich sein, die übrigen Daten in die Duplikatsuche miteinzubeziehen – indem Sie beispielsweise den Wohnort hinzunehmen und so vielleicht nur noch einen doppelten Klaus Müller zurückbehalten, den Sie über weitere Kriterien als Duplikat enttarnen – oder auch nicht.
Die in diesem Beitrag vorgestellte Lösung soll zunächst die Auswahl der zu untersuchenden Tabelle ermöglichen. Danach zeigt ein Unterformular alle Felder dieser Tabelle an und erlaubt das Festlegen der Felder, die in die Duplikatssuche mit einbezogen werden sollen. Außerdem können Sie dort einstellen, welche Details für die ausgewählten Datensätze angezeigt werden. Nach dieser Auswahl greifen Sie direkt auf die gefundenen Datensätze zu und können diese bearbeiten oder löschen.
Im Detail sieht das wie in Bild 1 aus. Die Auswahl der zu untersuchenden Tabelle erfolgt über ein Kombinationsfeld, das alle Tabellen der Datenbank mit Ausnahme der Systemtabellen anzeigt. Gleich nach dieser Auswahl füllt das Formular ein Unterformular mit einer Liste aller Felder der ausgewählten Tabelle. Daneben finden Sie zwei Spalten mit Kontrollkästchen.
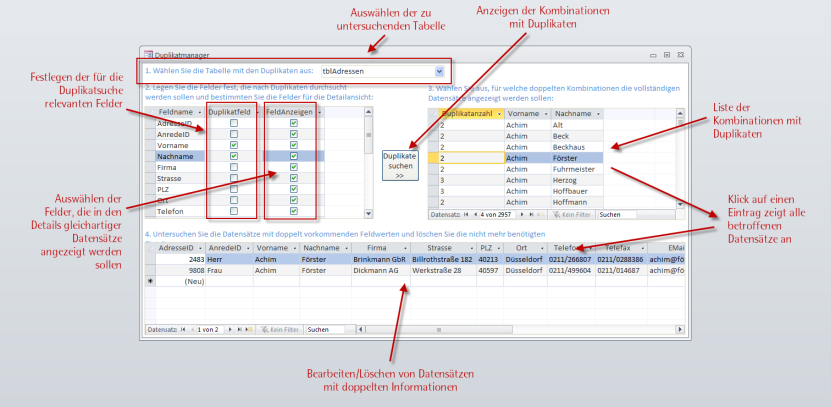
Bild 1: Übersicht der Funktionen des Duplikatmanagers
Die erste Spalte ermöglicht die Auswahl aller Felder, die in die Duplikatsuche mit einbezogen werden sollen. Wenn Sie dort beispielsweise die Felder Vorname und Nachname einer Adressentabelle auswählen, soll die Lösung zunächst prüfen, wieviele Datensätze es von jeder in der Tabelle vorhandenen Kombination von Vor- und Nachname gibt, und davon all diejenigen anzeigen, die mehr als zweimal vorkommen.
Dies schlägt sich im Unterformular oben rechts nieder, wo zuerst die Anzahl der Duplikate und dann der Wert der für die Duplikatsuche ausgewählten Felder erscheint.
Kommen wir noch einmal zurück zur Liste der Felder der ausgewählten Tabelle. Dort legen Sie nicht nur fest, nach welchen Feldern die Duplikate ermittelt werden sollen, sondern auch, welche Daten der gefundenen Datensätze in der Detailtabelle im Unterformular im unteren Bereich erscheinen sollen. Standardmäßig werden dort alle Felder markiert, Sie können nach Bedarf jedoch eines oder mehrere Felder abwählen.
Das Unterformular rechts oben zeigt nicht nur die mehrfach vorkommenden Kombinationen der gewählten Felder an, sondern ermöglicht es auch, alle betroffenen Datensätze im unteren Formular anzuzeigen. Wenn die Adressentabelle also zwei Datensätze mit dem Vornamen Achim und dem Nachnamen Förster enthält, können Sie die Details dieser beiden Datensätze durch einen einfachen Klick im unteren Unterformular anzeigen lassen.
Dort können Sie die Datensätze ganz normal bearbeiten und so etwa einen oder mehrere Datensätze löschen oder die Daten mehrerer Datensätze zu einem Datensatz zusammenführen.
Technische Beschreibung des Duplikatmanagers
Auf den folgenden Seiten erfahren Sie, wie der Duplikatmanager funktioniert. Bevor wir jedoch in den Aufbau des Formulars und seiner Unterformulare einsteigen, benötigen wir noch die theoretischen Hintergründe zu der hier verwendeten Duplikatsuche.
Aufbau der Abfrage zur Duplikatsuche
Bevor wir uns um die Definition der für die Duplikatsuche benötigten Abfragen kümmern, definieren wir die Anforderungen: Eine Abfrage zur Duplikatsuche soll alle Datensätze liefern, bei denen eine Kombination aus einem oder mehreren Feldern gleich ist, also zum Beispiel alle Datensätze, in denen Vor- und Nachname identisch sind.
Wichtig ist, dass die Duplikatsuche nicht nur die für die Suche berücksichtigten Felder zurückliefert, sondern auch noch weitere, wie etwa den Primärschlüsselwert der betroffenen Datensätze. Außerdem wird der Benutzer die Daten der übrigen Felder sehen wollen, um zu entscheiden, welcher Datensatz gelöscht und welcher beibehalten werden soll.
Damit können wir die benötigte Abfrage herleiten. Dabei brauchen wir zunächst einmal eine Abfrage, die alle Datensätze der betroffenen Tabelle sucht, die mehr als einmal vorkommen. Dazu muss die Abfrage zunächst einmal die Anzahl der Vorkommnisse einer jeden Kombination liefern. Eine solche Abfrage auf Basis der Tabelle tblArtikel aus der Beispieldatenbank erhalten Sie, wenn Sie zunächst die zu kombinierenden Felder hinzufügen (etwa Vorname und Nachname), die Abfrage nach diesen Feldern gruppieren und eines der beiden Felder zusätzlich als Basis einer Zählung verwenden. In der Entwurfsansicht sieht dies wie in Bild 2 aus, der SQL-Ausdruck liefert dieses Bild:
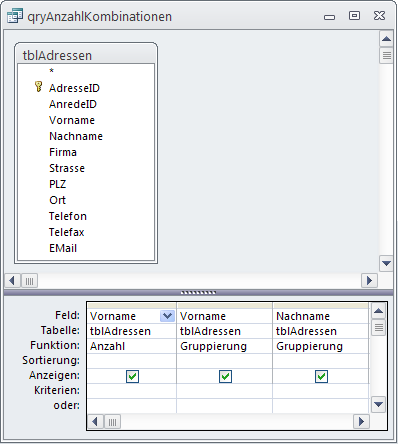
Bild 2: Diese Abfrage zeigt die Anzahl aller vorhandenen Kombinationen aus Vor- und Nachnamen an.
SELECT Count(Vorname) AS AnzahlvonVorname, Vorname, Nachname FROM tblAdressen GROUP BY Vorname, Nachname;
Uns interessieren nur diejenigen Datensätze dieser Abfrage, bei denen die Kombination aus Vor- und Nachname mehr als einmal vorkommt. Normalerweise würden Sie für den Vergleich mit einem Zahlenwert die WHERE-Klausel hinzuziehen. Wenn Sie aber nicht den Wert eines Feldes, sondern das Resultat einer Berechnung auf Basis einer Gruppierung als Kriterium verwenden möchten, benötigen Sie dazu die HAVING-Klausel. Bezogen auf das obige Beispiel kommt dann Folgendes heraus:
SELECT Count(Vorname) AS AnzahlvonVorname, Vorname, Nachname FROM tblAdressen GROUP BY Vorname, Nachname HAVING Count(Vorname)>1;
Das Ergebnis dieser Abfrage finden Sie in Bild 3. Nun hilft dies nur bedingt, denn wir wollen ja nicht nur jeweils ein Exemplar der mehrfach vorhandenen Datensätze sehen, sondern alle – und noch dazu sollen auch die übrigen Daten der zugrunde liegenden Tabelle erscheinen.
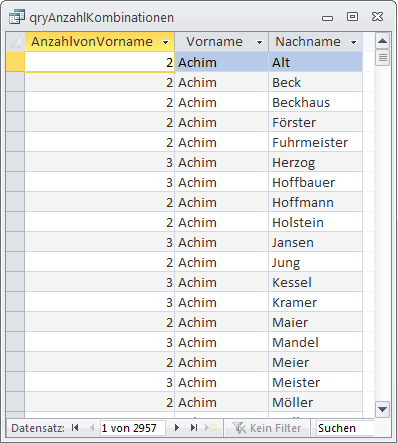
Bild 3: Zusammen mit einem entsprechenden Kriterium liefert die Abfrage alle Kombinationen aus Vor- und Nachname, die mehrmals vorkommen.
Dies funktioniert nur, wenn wir die bereits hergeleitete Abfrage umbauen und als Unterabfrage einer weiteren Abfrage definieren. Die Hauptabfrage soll dann alle Datensätze der Herkunftstabelle anzeigen, deren Vor- und Nachname mit den in der Unterabfrage ermittelten Duplikaten übereinstimmt.
Nun erlaubt eine Unterabfrage aber nur die Ausgabe eines einzigen Feldes, das als Kriterium eines Feldes der Hauptabfrage dient. Wenn wir in diesem Fall den Wert des Feldes Vorname verwenden, würden wir alle Datensätze der Tabelle erhalten, deren Vornamen mit den in der Unterabfrage ermittelten Vornamen übereinstimmen. Das heißt aber, dass wir den Nachnamen komplett unter den Tisch fallen ließen! Also gehen wir einen kleinen Umweg und legen in der Unterabfrage eine WHERE-Bedingung fest, mit der wir sicherstellen, dass die Hauptabfrage nur solche Datensätze anzeigt, deren Nachname mit dem Feld Nachname der Unterabfrage übereinstimmt. Und dies sieht dann so aus:
SELECT AdresseID, AnredeID, Vorname, Nachname, Firma, Strasse, PLZ, Ort, Telefon, Telefax, Email FROM tblAdressen WHERE Vorname In ( SELECT Vorname FROM tblAdressen GROUP BY Vorname, Nachname HAVING Count(Vorname)>1) );
Das Ergebnis dieser Abfrage sieht, nach Hinzufügen einer Sortierung nach Vorname und Nachname, wie in Bild 4 aus. So viel zur Theorie – nun kümmern wir uns um die Umsetzung in den angekündigten Assistenten.
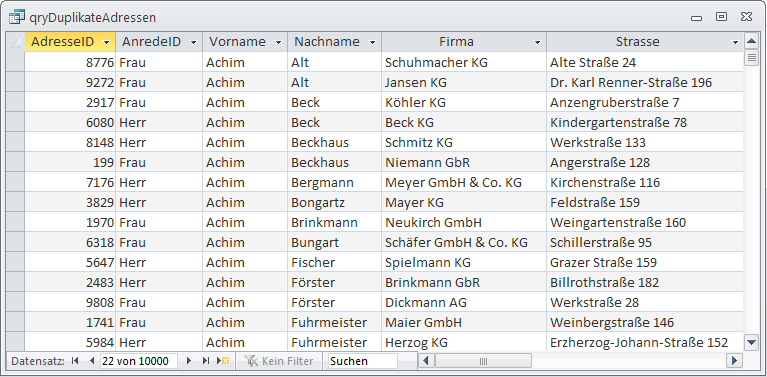
Bild 4: Ausgabe aller mehrfach vorhandenen Datensätze in einer einzigen Abfrage
Das Hauptformular
Das Formular frmDuplikatmanager dient als Hauptformular der Anwendung. Es soll keine Daten anzeigen, also stellen Sie seine Eigenschaften Trennlinien, Bildlaufleisten, Datensatzmarkierer und Navigationsleiste auf Nein ein.
Außerdem soll das Formular beim Öffnen zentriert erscheinen, was Sie durch Einstellen der Eigenschaft Automatisch zentrieren auf Ja erreichen. Das Formular beherbergt die folgenden Steuerelemente:
- cboTabellen: Kombinationsfeld zur Auswahl der zu untersuchenden Tabelle
- sfmDuplikatfelder: Unterformularsteuerelement zur Anzeige der Felder der mit dem Kombinationsfeld cboTabellen ausgewählten Tabelle. Das Unterformularsteuerelement zeigt das Formular sfmDuplikatfelder an.
- cmdDuplikateSuchen: Schaltfläche, um die in der angegebenen Tabelle enthaltenen Duplikate entsprechend den für die Duplikatsuche ausgewählten Feldern zu ermitteln.
- sfmDuplikate: Unterformularsteuerelement zur Anzeige der gefundenen Kombinationen der angegebenen Felder samt Anzahl der Duplikate. Enthält das flexibel mit Daten zu füllende Formular sfmFlex. Als Datenherkunft dient die erst zur Laufzeit erstellte Abfrage _qryDuplikate.
- sfmDuplikatdetails: Unterformularsteuerelement zur Anzeige der Details des im Unterformularsteuerelement sfmDuplikate ausgewählten Eintrags. Enthält kein Formular als Herkunftsobjekt, sondern die Abfrage _qryDuplikateDetail, die dynamisch auf Basis der gemachten Angaben erstellt wird.
Die Anwendung enthält einige weitere Objekte, die für die Ausführung unentbehrlich sind:
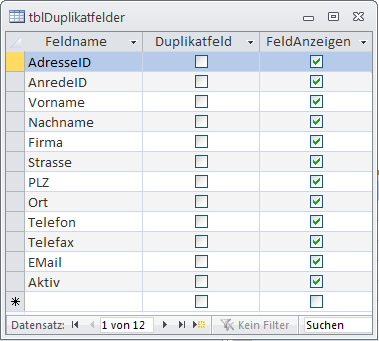
- Die Tabelle tblDuplikatfelder speichert alle Felder, die in der mit dem Kombinationsfeld cboTabellen ausgewählten Tabelle enthalten sind. Gefüllt mit den Feldern einer einfachen Adressentabelle sieht die Tabelle etwa wie in Bild 5 aus.
Ende des frei verfügbaren Teil. Wenn Du mehr lesen möchtest, hole Dir ...
Testzugang
eine Woche kostenlosen Zugriff auf diesen und mehr als 1.000 weitere Artikel
diesen und alle anderen Artikel mit dem Jahresabo