
„Firma Waren-Paradies, Konstanze Meyer am Apparat. Was kann ich für Sie tun“ – „Ja, Katschmarek. Ich hatte letzte Woche eine Bestellung aufgegeben; die möchte ich gerne stornieren.“ – „Wie war der Name“ – „Katschmarek!“ Die Kundenbetreuerin Frau Meyer gibt den Namen in die Suchmaske des Kundenformulars ihrer Datenbank zur Bestellabwicklung ein. Die Datenbank findet den Kunden nicht. „Würden Sie den Namen bitte buchstabieren“ – „K-A-C-S-M-A-R-E-K“ – „Mit C-S“ – „Ja, genau!€ Ein Glück, dass Herr Kacsmarek nicht mit „Kaufmann-Anton-Cäsar-Samuel-Martha-…“ antwortete, denn dann hätte Frau Meyer wahrscheinlich nochmals nachgefragt …
Dieser Fall ist wohl nicht selten. Hat man nur das gesprochene Wort zur Verfügung, so dürfte man mit der korrekten Schreibweise gerade von Namen häufig überfordert sein. Eine Datenbank, die Begriffe nur anhand exakter Übereinstimmung vergleicht, wird dem nicht gerecht.
Dabei hätte der Entwickler der Datenbank Frau Meyer die Sache leichter machen können, wenn er Methoden zur fehlertoleranten Suche, eine „Unscharfsuche“, eingebaut hätte. Solche Routinen versuchen, zwei Begriffe auf größtmögliche Übereinstimmung zu vergleichen, und geben die plausibelsten Treffer in einer Liste zurück, aus der man schließlich den wahrscheinlichsten auswählen kann.
Anwendungsbereiche für eine solche fehlertolerante Suche gibt es viele: Außer Nachnamen wären etwa Straßennamen Kandidaten, Bezeichnungen von Artikeln, Ländernamen oder selbst Telefonnummern, die Zahlendreher enthalten. Wenn auch Sie den Benutzern Ihrer Datenbanken ähnlichen Komfort bieten möchten, dann integrieren Sie einfach eine Lösung, wie die nachfolgend vorgestellte.
Was ist ähnlich
Bevor man einen Algorithmus entwickelt, der zwei Strings auf ähnlichkeit untersucht, muss man sich zunächst fragen, was unter „ähnlichkeit“ überhaupt zu verstehen ist. Was für den Cortex eines Menschen kein Problem zu sein scheint, bereitet dem Linguisten und erst recht dem Programmierer erhebliches Kopfzerbrechen.
Zudem kann die Fehlerquelle für falsche Schreibweise auch noch ganz unterschiedlich sein. Im Beispiel oben handelt es sich um ein phonetisches Problem: die Aussprache beider Begriffe ist identisch, ihre Länge unterscheidet sich aber um zwei Buchstaben. Von den Lauten her hat Frau Meyer nichts falsch gemacht.
Doch selbst dann, wenn sie ungarische Vorfahren hätte und die richtige Schreibweise wüsste, hätte ihr ein Schreibfehler unterlaufen und die Eingabe „Kascmarek“ sein können – sie hat sich schlicht vertippt. Die Aufgabe liegt also darin, einerseits Schreib- und Tippfehler aufzufangen und andererseits phonetische ähnlichkeiten zu erkennen.
Die rein programmtechnische Frage ist außerdem, wie eine ähnlichkeitsfunktion das Maß der Übereinstimmung widergeben soll. Es haben sich hier zwei Verfahren eingebürgert, die sinnbildlich so aussehen:
fuSimilar ("Begriff1" , "Begriff2") = TRUE oder FALSE
fuSimilar ("Begriff1" , "Begriff2") = 0...100
Im ersten Fall sagt die Funktion lediglich, ob die Begriffe überhaupt ähnlich sind oder nicht (Ja oder Nein).
Im zweiten wird ein Wert zurückgegeben, der mit 100 völlige Übereinstimmung, mit 0 überhaupt keine und dazwischen teilweise Übereinstimmung feststellt.
Phonetik
Viele Algorithmen spezialisieren sich darauf, Begriffe zu vergleichen, die gleich oder möglichst ähnlich ausgesprochen werden. Dazu werden, bevor es zum eigentlichen String-Vergleich kommt, zunächst beide Begriffe einer phonetischen Analyse unterzogen.
Nehmen wir mal den Namen „Becker“. Hier besteht die deutsche Eigentümlichkeit darin, dass ein „CK“ genau so ausgesprochen wird, wie das „K“ allein. Man könnte den String also analysieren und das „CK“ zunächst durch ein „K“ ersetzen.
Nach dieser Vorbehandlung wären die beiden Begriffe „Becker“ und „Beker“ identisch. Ein Algorithmus mit phonetischem Präprozessor würde nun den Wert 100 für den Vergleich zurückgeben.
Da dies nicht wirklich zutrifft, ziehen die gängigen Algorithmen hier einfach einen kleinen Ausgleichswert ab – etwa 10 -, falls der Präprozessor tatsächlich an den Eingangs-Strings geschraubt hat. In diesem Fall wäre das Ergebnis folglich 90, was man als „so gut wie, aber nicht identisch“ interpretieren könnte.
Das Beispiel bietet noch mehr Potenzial: Im Deutschen lauten „E“ und „ä“ gleich. Somit kann ein „ä“ ebenfalls durch ein „E“ ersetzt werden. Das „ä“ wiederum könnte auch umlautlos als „AE“ daherkommen. Folgende Namen wären dann nach Durchlaufen des Präprozessors identisch:
"Becker", "Beker", "Bäker", "Bäcker", "Baeker", "Baecker"
Alle sechs resultierten im vorbehandelten String „Beker“.
Zu überlegen wäre auch, ob nicht Vokalverdoppelungen reduziert werden könnten:
"Beeker" > "Beker"
Das Spiel kann beliebig fortgesetzt werden. So ist die Endung „er“ im Deutschen etwa weitgehend lautgleich mit „a“. Aus „Becker“ würde „Beka“.
Damit das funktioniert, reicht ein einfaches Replace auf die Eingangs-Strings allerdings nicht aus. Soll alles korrekt laufen, so muss ein Begriff eigentlich in Silben aufgetrennt, die Position einer Zeichenkombination ermittelt und außerdem analysiert werden, ob vor einer Konsonantenkombination ein Vokal steht oder nicht.
Und damit wären wir schon bei den Nachteilen eines phonetischen Präprozessors: Die Berechnung kostet sehr viel Zeit und ist nicht sehr zuverlässig, weil etwa eine Silbentrennung nicht mit hinreichender Performance zu bewerkstelligen ist.
Außerdem funktioniert der phonetische Präprozessor nur für eine bestimmte Sprache. Im Slawischen etwa würde der Name „Becker“ eher wie „Betschker“ ausgesprochen. Wäre die Zielsprache also Serbisch, so benötigte man dafür einen völlig anderen Präprozessor.
Gerade für Namensvergleiche eignet sich das Verfahren daher weniger, weil – siehe Eingangsbeispiel „Kacsmarek“ – internationale Namen im deutschen Sprachraum immer häufiger vorkommen.
Aus Performancegründen verwenden ähnlichkeitsalgorithmen deshalb normalerweise nur sehr einfache phonetische Präprozessoren. Im Ergebnis sind sie dann mal besser, mal schlechter als Algorithmen ohne Präprozessor. Es kommt immer auf den genauen Anwendungsbereich an, ob man sie einsetzen sollte oder nicht.
In der später vorgestellten Demo können Sie sich selbst ein Bild davon machen. Zwei der verwendeten Algorithmen können optional auch mit phonetischem Präprozessor betrieben werden. Testen Sie einfach, ob die phonetische Vorbehandlung etwas bringt.
Vertippt
Sie kennen das sicher: Sie tippen schnell mal ein Wort in die Tastatur und haben schließlich statt „Becker“ den Text „Bekcer“ auf dem Schirm – ein Verdreher. Oder die letzte Taste wurde nicht richtig gedrückt, was „Becke“ zum Ergebnis hat.
Aufgabe der Datenbank soll nun sein, trotzdem den beabsichtigten Begriff zu finden. Wie kann man das anstellen
ähnlichkeitsalgorithmen
Fast alle gängigen Algorithmen verwenden für unseren Zweck das sogenannte Distanz-Verfahren. Am bekanntesten ist die Levenshtein-Distanz, benannt nach ihrem Schöpfer.
Dabei wird ermittelt, wie viele Zeichen der Eingangs-Strings jeweils an der gleichen Position genau übereinstimmen, beziehungsweise, ob sich eine übereinstimmende Position möglicherweise in der Nähe befindet.
Sehen wir uns „Becker“ vs. „Bekcer“ näher an (s. Bild 1). An vier Positionen befinden sich übereinstimmende Zeichen, die den Gewichtungsfaktor 1 bekommen. Bei zwei Zeichen gibt es jeweils Übereinstimmung an um eins verschobenen Positionen. Diese werden nun willkürlich mit dem Faktor 0.5 belegt, was aussagen soll, dass eine mögliche Gleichheit besteht.
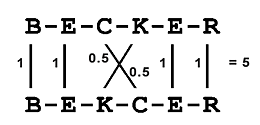
Bild 1: Vergleich von Becker und Bekcer
Bereits hier wird sichtbar, dass solche Berechnungen die Realität nur annähernd widerspiegeln und auf reinen, zum Teil stochastischen Annahmen beruhen. Und genau dies ist die Kunst solcher Algorithmen: Sie sollen dem, was ein Mensch als ähnlich empfindet, möglichst nahekommen.
Deshalb gibt es auch Hunderte solcher Verfahren, die sich manchmal nur in kleinen, aber wichtigen Details unterscheiden, und ganze Studienprojekte beschäftigen ihre Eleven mit der Optimierung solcher Routinen.
Wer hier einen näheren Blick riskieren will, der schaue sich auf der Seite von SimMetrics [1] um, einem Open-Source-Projekt der englischen Universität Sheffield. Dort sind zahlreiche Algorithmen in einem Projekt zusammengefasst und bewertet worden, das auch als Visual Studio.NET-Paket zur Verfügung steht.
Die jeweiligen Algorithmen sind darin übersichtlich in einzelnen C-Libraries abgelegt. Zur Warnung: Wie bei Uni-Projekten üblich, ist der Verständnis-Level hier nur eine Sache für wissenschaftlich Interessierte.
Um beim Beispiel zu bleiben – in Bild 2 hat sich jemand noch mehr vertan. Die Buchstaben sind ziemlich durcheinander und doch erkennt man mit dem Auge auf einen Blick, dass ähnlichkeit zwischen beiden Begriffen besteht, obwohl nur drei Zeichen an der korrekten Position übereinstimmen. Die anderen sind mehr oder weniger verschoben und dem tragen die Faktoren 0.5 und 0.25 Rechnung.
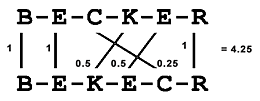
Bild 2: Vergleich von Becker und Bekecr
Letztlich summiert man nun die Gewichtungsfaktoren und setzt sie in Beziehung zur durchschnittlichen Gesamtzahl an Zeichen beider Strings. Im letzten Beispiel:
f = 4.25/6 = 0.7083
Da die Rückgabewerte im Bereich von 0 bis 100 liegen sollen, wird dieses Ergebnis noch mit 100 multipliziert, gerundet und Sie erhalten 71.
In der praktischen Auswertung würde man nun ein Limit setzen und annehmen, dass etwa alle Ergebnisse oberhalb von 75 als hinreichend ähnlich anzusehen seien. In diesem Fall fiele das letzte Beispiel aus der Liste der plausiblen Ergebnisse heraus, das vorige aber genügte der Bedingung:
f = Round (5/6 * 100) = 83
Übrigens kommt derselbe Wert auch dann heraus, wenn man „Becker“ und „Wecker“ vergleicht. Dieses Ergebnis kann man schon weniger akzeptieren. Doch dafür gibt es leider keine Regel: Es hat sich stochastisch schlicht ergeben, dass der Anfangsbuchstabe seltener falsch geschrieben wird.
Also belegen viele Verfahren den ersten oder die ersten Zeichen beim Vergleich mit höheren Gewichtungsfaktoren. Würde man etwa die Übereinstimmung des ersten Zeichens mit dem Faktor 2 versehen, dann sähe die Rechnung wie folgt aus:
"BECKER" vs. "BECLER"
Fünf Zeichen stimmen überein, eines nicht. Das erste Zeichen bekommt aber den Faktor 2, sodass die Summe 6 ergibt. Der eine Faktor 2 muss nun natürlich in den Längendivisor mit einbezogen werden, weshalb als Ergebnis 6/(6+1) = 86 steht.
"BECKER" vs. "WECKER"
Auch hier stimmen fünf Zeichen überein. Da der Anfangsbuchstabe jedoch falsch ist, fehlt nun der Faktor 2: 5/6 = 83.
In einer Liste möglicher Treffer, die absteigend nach dem ähnlichkeitswert sortiert wäre, befände sich also „BECLER“ weiter oben.
Abschließend der Hinweis, dass diese Darstellung lediglich das Grundprinzip des Distanzverfahrens widergibt. Die tatsächlichen Implementationen sind deutlich komplexer. Um diese brauchen Sie sich allerdings auch nicht weiter zu kümmern, denn Sie selbst werden wahrscheinlich keine eigenen Algorithmen entwickeln wollen. Überlassen Sie das ruhig den Professoren an den Instituten.
Es ist nur gut zu wissen, wie die Verfahren prinzipiell arbeiten, um deren Ergebnisse besser interpretieren zu können.
Implementationen
Von den Verfahren, die weite Verbreitung erfahren haben, ist in erster Linie der uralte Soundex-Algorithmus (1918!) zu erwähnen. Dieser abstrahiert Eingabe-Strings stark, indem er daraus einen Zeichencode mit genau vier Zeichen erzeugt.
Dabei werden nur die vorderen Buchstaben berücksichtigt, die hinteren abgeschnitten und außerdem Buchstabengruppen Zahlen zugeordnet. Es werden auch nur Konsonanten in die Berechnung einbezogen.
Aus „Becker“ wird etwa „B226“. Den exakt gleichen Code erhält man auch mit der Eingabe „Busserl“. Soundex sieht zwei Strings als ähnlich an und gibt dann eine 1 aus, wenn die errechneten Codes genau übereinstimmen, und andernfalls eine 0. Im Grunde handelt es sich damit bei Soundex um einen Präprozessor.
Ob „Becker“ und „Busserl“ tatsächlich ähnlich sind, mag jeder selbst entscheiden, und außerdem, ob die Ausgabewerte 1 und 0 den Anforderungen an eine fehlertolerante Suche wirklich genügen. Abgesehen davon, dass Soundex nur den Anfang eines Begriffs untersucht, die Konsonanten stark reduziert und Vokale außen vor lässt, ist er auch noch auf die englische Sprache „optimiert“.
Ich mache keinen Hehl aus meiner Einschätzung, dass Soundex für eine ernsthafte ähnlichkeitssuche nicht zu gebrauchen ist, obwohl er sogar in die SQL-Funktionen von DBMS wie MSSQL, Oracle und MySQL aufgenommen wurde – warum auch immer.
Daran ändert leider auch der abgeleitete und etwas verbesserte Metaphone-Algorithmus nichts. Metaphone erzeugt nicht nur vier Zeichencodes, sondern beliebig lange, und teilt die Konsonanten nicht nur in sechs Gruppen ein. Er ist aber ebenso auf die englische Sprache abgestimmt und gibt als Ergebnis lediglich eine 1 oder eine 0 zurück.
Diese beiden Algorithmen sind hier nur der weiten Verbreitung wegen erwähnt worden. Mit dem oben dargestellten Distanzverfahren haben sie nichts zu tun. Dessen wichtigster Vertreter wiederum ist der bereits 1965 entwickelte Levenshtein-Algorithmus.
Er arbeitet im Prinzip ziemlich genau so, wie im „Becker-Beispiel“ erläutert, hat aber den Nachteil, dass keine variablen Gewichtungen eingerechnet werden und kein Präprozessor vorgesehen ist.
Deshalb haben sich Myriaden von Entwicklern an seine Verbesserung gemacht. Daraus haben sich Verfahren wie Ratcliff/Obershelp und die von Jaro und Winkler ergeben. Beide sind relativ neueren Datums – entwickelt Mitte der Neunziger Jahre – und kommen in der Demo zu diesem Beitrag zum Einsatz.
Wie sie genau funktionieren, lasse ich außen vor und ebenso die ganzen anderen Verfahren, die Sie etwa im SimMetrics-Paket [1] finden können.
Beispieldatenbank
Starten Sie die Beispieldatenbank similar.mdb, die lediglich ein Formular (s. Bild 3) enthält, in dem ein wählbarer Name nach verschiedenen Methoden mit 10.000 Stammdatensätzen auf ähnlichkeit verglichen wird. Als Ergebnis erhalten Sie eine gefilterte Liste der zutreffendsten Nachnamen aus der Stammdatentabelle.
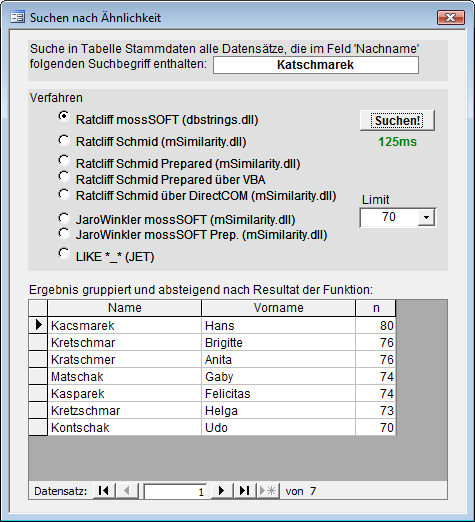
Bild 3: ähnlichkeitsvergleich eines Namens mit den Stammdaten einer Tabelle
Die Datenbank greift teilweise auf externe Komponenten zu, auf die Verweise gesetzt sind. Das sind die beiden ActiveX-DLLs dbstrings.dll und mSimilarity.dll. Damit beim Start der Demo keine Fehlermeldungen wegen nicht vorhandener Verweise auftauchen, müssen diese beiden DLLs zunächst im System registriert werden.
Dazu führen Sie einfach die Datei register_dll.bat aus. Unter Vista und Windows 7 muss sie dezidiert mit Als Administrator ausführen aufgerufen werden, unter Windows XP sollten Sie unter einem Administrator-Account arbeiten.
Die Stammdatentabelle, auf die das Formular aufsetzt, ist sehr einfach gestrickt: Neben der Primärschlüssel-ID gibt es nur ein Feld für Nachname (Name) und eins für den Vornamen einer Person.
Unser exklusives Angebot für Dich!
(Gilt für den Abschluss eines Jahres-Abonnements im ersten Jahr, danach 189,-/Jahr)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →